> library(adabag)
> index<-sample(c(1, 2), nrow(iris), replace=T, prob=c(0.7, 0.3))
> train<-iris[index==1, ]
> test<-iris[index==2, ]
>
> result<-bagging(data=train, Species~.)
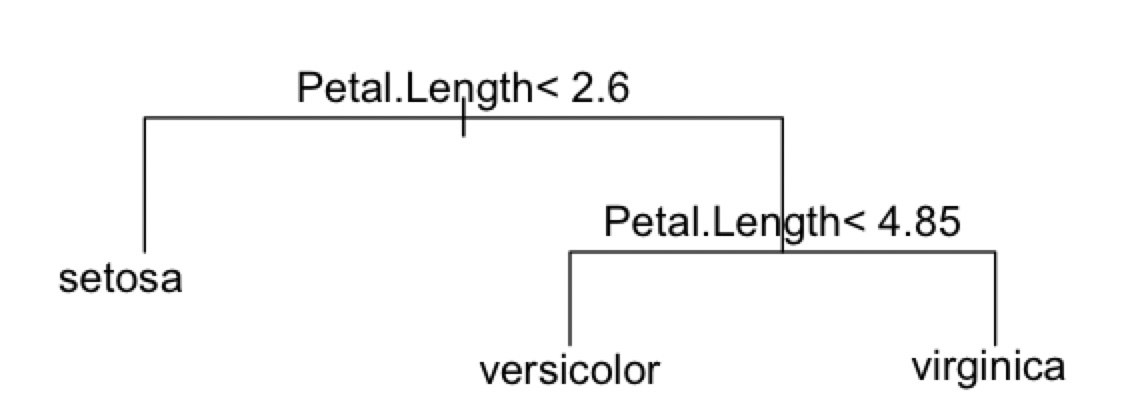
> plot(result$trees[[1]], margin=0.3)
> text(result$trees[[1]])
> plot(result$trees[[100]], margin=0.3)
> text(result$trees[[100]])

> pred<-predict(result, newdata=test)
> table(condition=test$Species, pred$class)
condition setosa versicolor virginica
setosa 14 0 0
versicolor 0 16 0
virginica 0 0 9
# pred$confusion으로도 결과 확인 가능
> pred$confusion
Observed Class
Predicted Class setosa versicolor virginica
setosa 14 0 0
versicolor 0 16 0
virginica 0 0 9